

Как использовать парсинг без кода? В этом руководстве мы будем использовать инструменты No Code для парсинга сайта электронной коммерции и отправки предупреждающего текста с помощью сервиса Zyte API, интегратора n8n и мессенджера Telegram.
Как не пропустить распродажу
Представим ситуацию – я меломан, который постоянно находится в поиске предложений на наушники, колонки и качественную аудиотехнику. Headphone Zone – мое любимое место для таких покупок, поскольку там регулярно проводятся распродажи, а я люблю выгодные предложения. Но часто бывает так, что я тупо пропускаю эти распродажи! Почему, потому что письма с объявлениями о них теряются в потоке рекламных писем и спама. Я может и не против этих рассылок, но я не хочу посещать эти сайты каждый день. Поэтому я предпочитаю получать оповещения о распродажах на свой аккаунт в Telegram.
А будучи гиком:) я решил посмотреть, смогу ли я использовать некоторые простые инструменты без кода (потому что почему бы и нет) и API для веб-скрапинга (например Zyte API), чтобы создать систему, которая отправит мне уведомление всякий раз, когда на Headphone Zone будет распродажа. Это и будет мой личный парсинг без кода и программирования!
Теперь, я могу быть уверен, что не пропущу ни одного выгодного предложения на аудиоустройства. Хорошая новость заключается в том, что это оказалось на удивление просто, поэтому я собираюсь показать вам, как это сделать. Звучит заманчиво, правда? Итак начнем. Ключ на старт 🚀
Как это работает
Вот что нужно сделать, чтобы реализовать парсинг без кода:
- Установите инструмент интеграции без кода (n8n) для управления различными необходимыми инструментами и задачами
- Настройте API для веб-скрапинга и автоматически отслеживайте состояние заданного сайта
- Определите с помощью автоматического парсинга, есть ли распродажа
- Отправьте оповещения каждый раз на телефон через мессенджер Telegram
Введение в n8n и Zyte API
n8n – это инструмент для автоматизации рабочих процессов без кода. Он позволяет автоматизировать процессы, основанные на данных, и объединить ваши приложения в единый рабочий процесс. n8n предоставляет пользовательский интерфейс drag-and-drop, который позволяет создавать рабочие процессы без написания кода.
Zyte API – это API, который призван решить все проблемы, связанные с извлечением данных из веб-страниц. В него встроено прозрачное решение для защиты от бана с ротацией IP-адресов, эмуляцией браузера и точной настройкой под конкретный сайт. В двух словах, Zyte API гарантирует, что вы не попадете под бан и доставите свои данные без каких-либо заминок.
Настройка n8n и получение ключа Zyte API
n8n – парсинг без кода
Самый простой способ начать работу с n8n – это приложение для настольных компьютеров. Ознакомьтесь с руководством по быстрому запуску для получения дополнительной информации.
Zyte API Key – парсинг без кода
Для Zyte API вам просто нужно зарегистрироваться на сайте https://app.zyte.com/account/signup/zyteapi и получить ключ Zyte API. Для получения пошагового руководства вы можете обратиться к этому руководству. Держите этот API-ключ под рукой, мы будем использовать этот API позже в рабочем процессе.
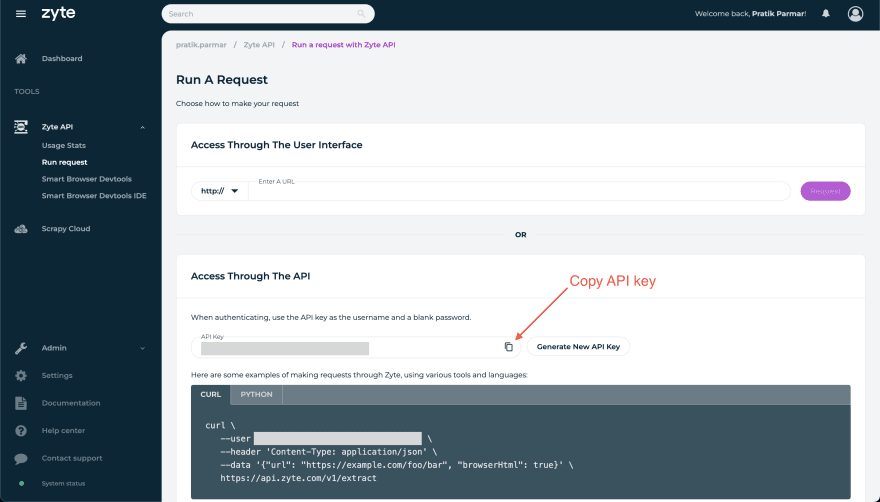
Учетные данные бота Telegram
В Telegram зайдите в чат BotFather и создайте нового бота. BotFather предоставит токен бота, который можно использовать для интеграции бота в любую платформу.
И последнее, что нам понадобится, – это идентификатор чата Telegram.
Как работает рабочий процесс веб-скрапинга в n8n
- Передайте в cURL URL-адрес сайта, который вы хотите парсить. Здесь это
https://www.headphonezone.in/collections/clearance. - С помощью узла HTTP-запроса выполните вызов Zyte API, чтобы получить HTML-контент
- Используйте узел HTML Extract для извлечения данных из HTML-контента
- Очистите данные и отправьте их с помощью узла Telegram.
Настройка рабочего процесса
Чтобы создать новый рабочий процесс n8n и реализовать парсинг без кода, просто перейдите в рабочий процесс и нажмите на кнопку new, чтобы создать новый рабочий процесс.
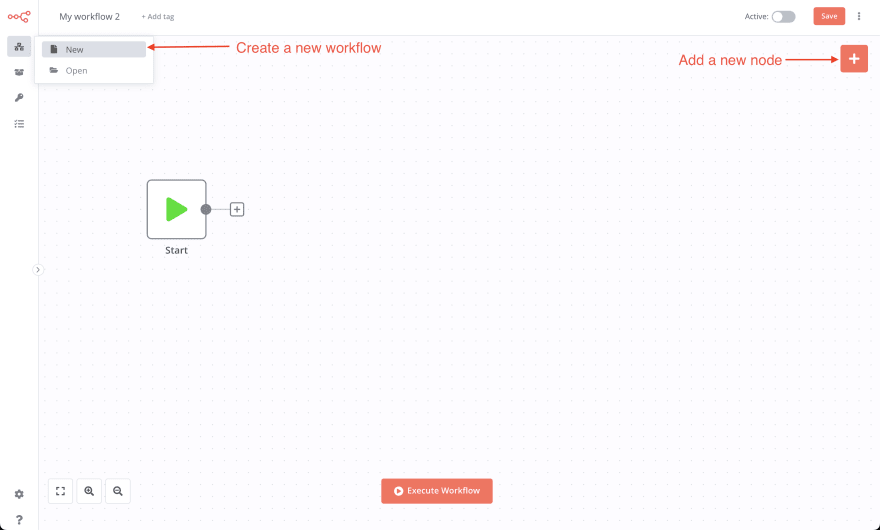
Рабочий процесс n8n состоит из небольших исполняемых блоков, называемых узлами.
Вы можете установить любые узлы, нажав на кнопку “+” в правом верхнем углу приборной панели n8n и выбрав один из доступных узлов
Получение данных сайта
Для загрузки HTML-данных с сайта нам понадобится узел HTTP Request. Добавив его в рабочий процесс, вам нужно будет указать URL-адрес сайта, с которого вы хотите получить данные. Вы также можете указать любые другие параметры запроса, такие как метод, заголовки и тело, если это необходимо.
Кроме того, для настройки этого узла можно использовать cURL. Нажмите кнопку Импорт cURL. Вставьте следующий cURL-запрос и импортируйте его. Убедитесь, что вы обновили свой ключ API Zyte здесь.
curl \
--user YOUR_ZYTE_API_KEY_HERE: \
--header 'Content-Type: application/json' \
--data '{"url": "https://www.headphonezone.in/collections/clearance", "browserHtml": true}' \
https://api.zyte.com/v1/extractВ конфигурации узла перейдите к опциям и добавьте опцию Response. Установите формат ответа как Text и установите Put Output in Field как response.
Нажмите на кнопку execute, чтобы убедиться, что все работает правильно.
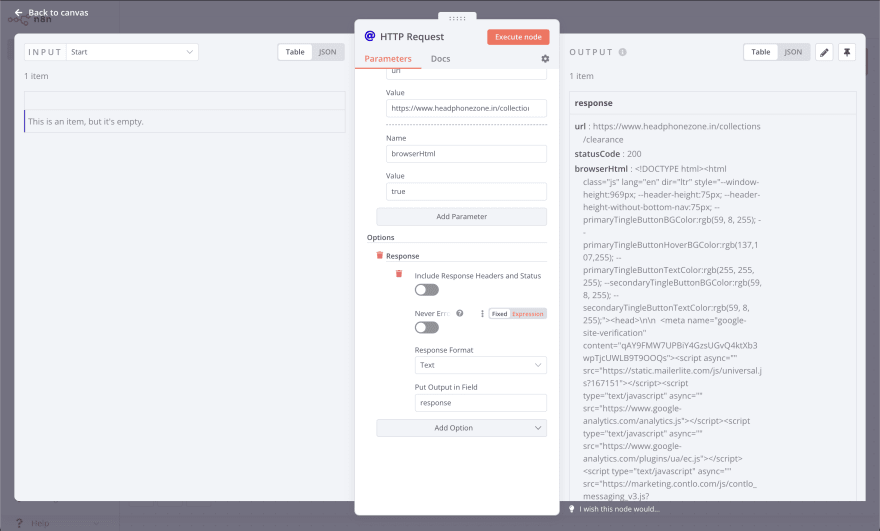
Получение HTML-содержимого с помощью узла Set
Теперь, если вы заметили, ответ от узла HTTP Request находится в JSON. Для нашего рабочего процесса нам нужен только browserHtml, который представляет собой HTML-содержимое веб-страницы. Мы можем использовать узел Set, чтобы создать еще одно поле 'data' и назначить browserHtml этому полю.
- Keep Only Set: Enable
- Values to Set:
- String
- Name:
data - Value:
{{$json["response"]["browserHtml"]}}
Этот узел получит поле browserHtml из поля response, которое является полем JSON, и установит его в поле data с типом данных string.

Извлечение данных о продукте из данных HTML
В узле HTML Extract вы можете использовать CSS-селекторы для извлечения нужных данных из HTML-ответа, полученного узлом HTTP Request. Вы можете указать элемент или атрибут, который нужно извлечь, введя CSS-селектор в поле Selector.
- Узел: HTML
- Исходные данные: JSON
- Свойство JSON:
data
Мы сохранили browserHtml в переменной data в предыдущем узле Set.
Извлечение значений
- Ключ:
products - Селекторы CSS:
.product-item
.product-item – это основной элемент, в котором хранятся все сведения о товаре.
- Возвращаемое значение: HTML
- Возвращаемый массив: Enable
Сохраните ответ в виде HTML в форме массива.
После выполнения результат должен выглядеть следующим образом.
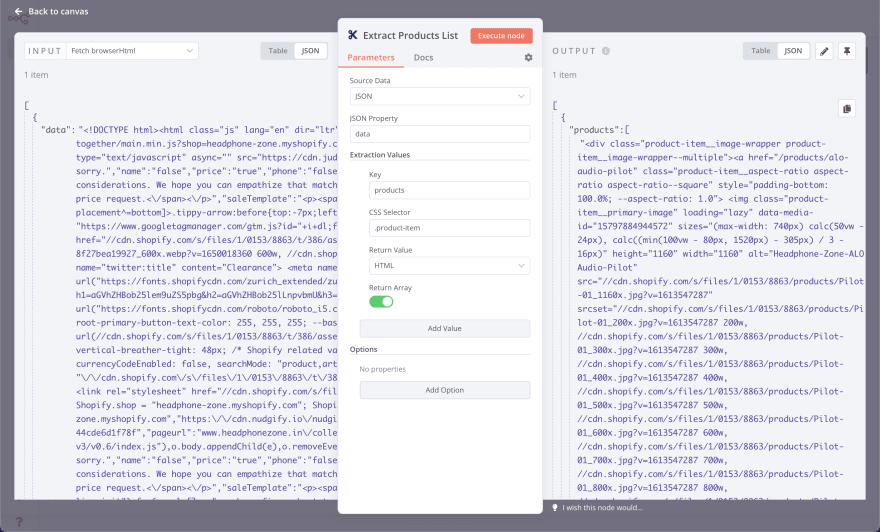
Теперь мы видим, что получили HTML-данные всех товаров. Но нам нужна человекочитаемая информация, причем по отдельности.
Поэтому давайте сначала разделим ее с помощью узла Item Lists.
- Node: Item List
- Operations: Split Out Items
- Field To Split Out: products
- Include: No Other Fields
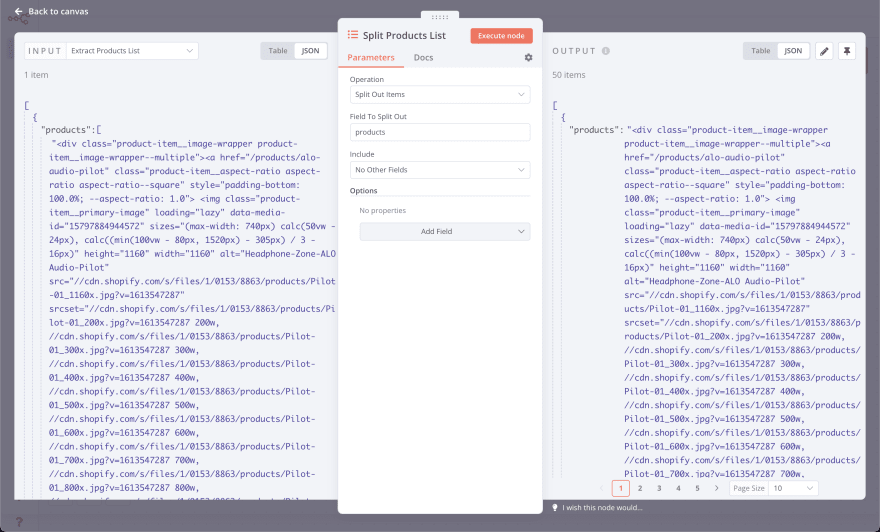
Извлечение отдельных продуктов
Хорошо, теперь у нас есть поле products, которое содержит данные обо всех товарах в формате HTML. Все, что нам нужно сделать, это извлечь информацию о продукте с помощью узла HTML Extract.
- Node: HTML Extract Node
- Source Data: JSON
- JSON Property:
products
Значения извлечения:
- Extract Product Name
- Key:
name - CSS Selector:
.product-item-meta__title - Return Value: Text
- Extract Product URL
- Key:
url - CSS Selector:
.product-item-meta__title - Return Value: Attribute
- Attribute:
href - Extract Product Price
- Key:
price - CSS Selector:
.price--highlight - Return Value: Text
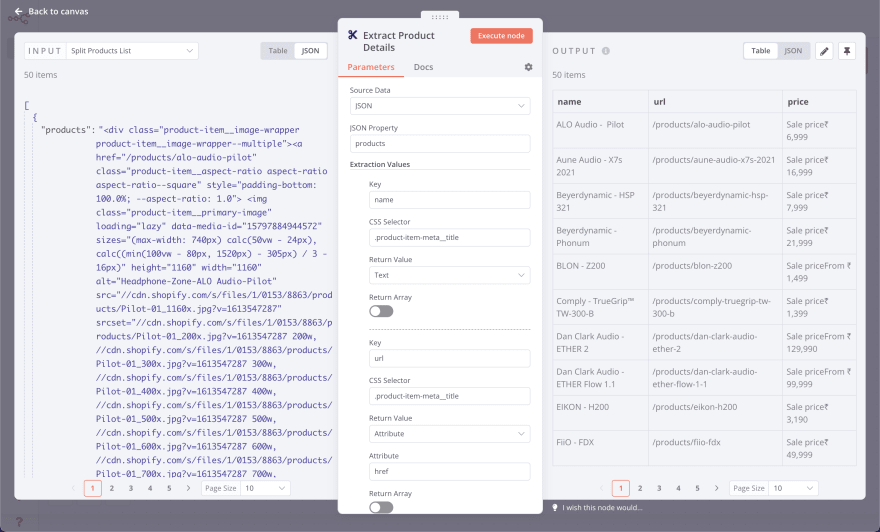
После выполнения узла он должен отобразить подробную информацию о товаре.
Отправка сообщения в Telegram
Фух, это было весело! Но это еще не все! Пора добавить узел Telegram Node для отправки сообщений боту Telegram, которого мы создали ранее.
Прежде всего, добавьте учетные данные для Telegram API и укажите токен бота.
- Node: Telegram
- Resource: Message
- Operation: Send Message
- Chat ID: Provide the Telegram chat ID we received earlier.
- Text:
{{ $json["name"] }}
https://www.headphonezone.in/{{ $json["url"] }}
{{ $json["price"] }}
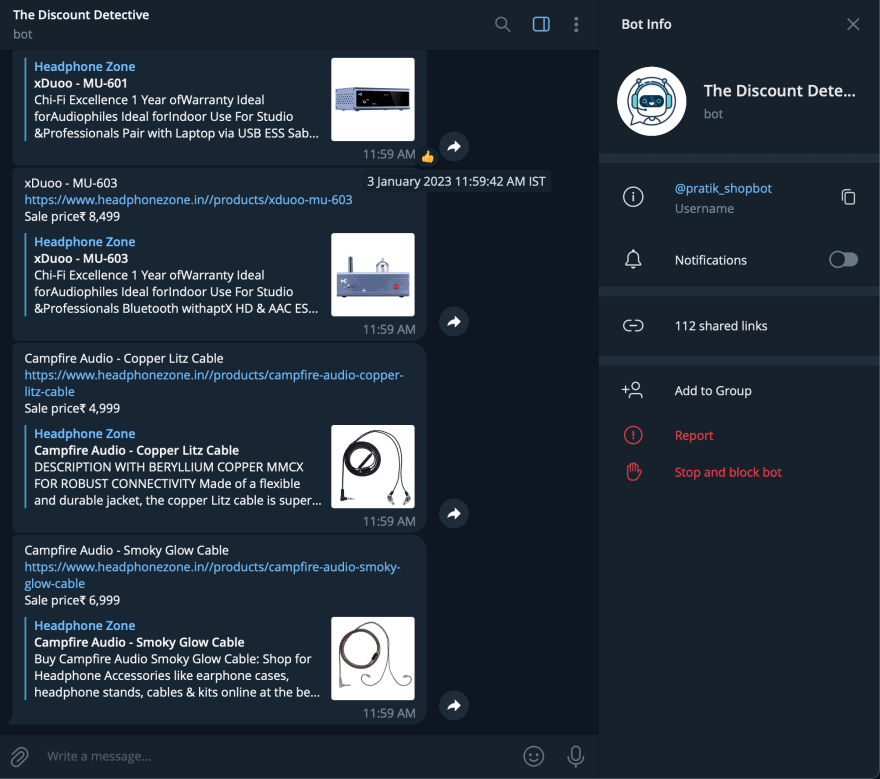
Этот текст выведет сообщение в таком формате в Telegram:
TIN HiFi - T5
https://www.headphonezone.in//products/tin-hifi-t5
Sale price₹ 9,999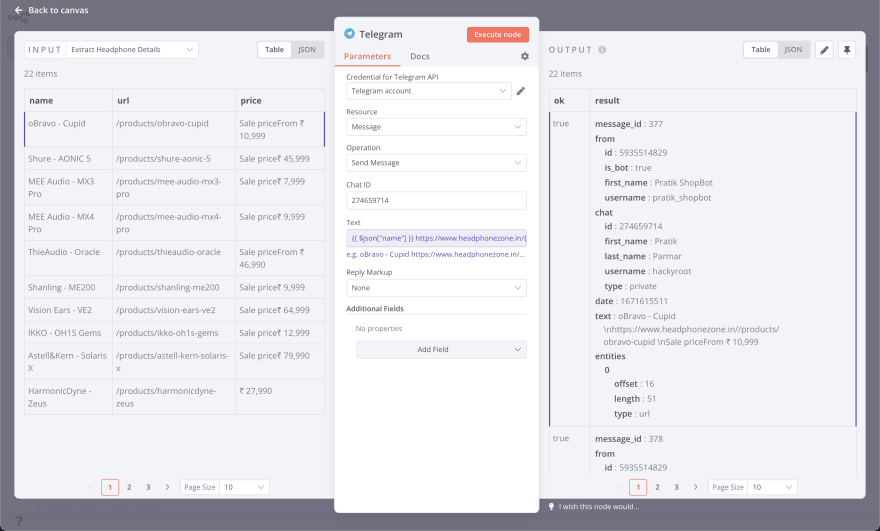
И вуаля! Если все работает хорошо, вы можете получать сообщения на бота Telegram!
Автоматизируем рабочий процесс
В настоящее время нам все еще нужно выполнять рабочий процесс вручную.
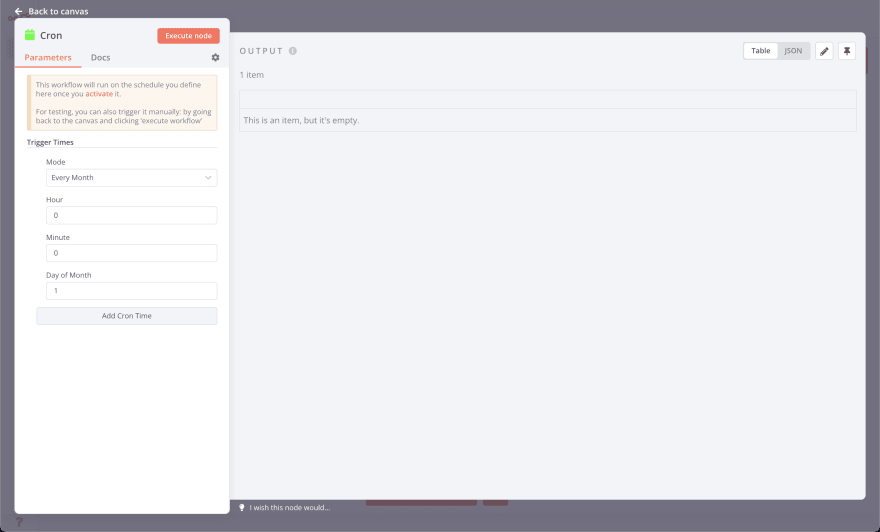
Какой смысл в автоматизации рабочего процесса, если его нужно запускать вручную? К счастью, в n8n также есть узел cron. Давайте добавим этот узел в рабочий процесс и удалим узел запуска.
Здесь я хочу выполнять этот рабочий процесс первого числа каждого месяца в полночь, так что вот как выглядит конфигурация:
Время срабатывания:
- Mode: Every Month
- Hour: 0
- Minute: 0
- Day of the Month:1
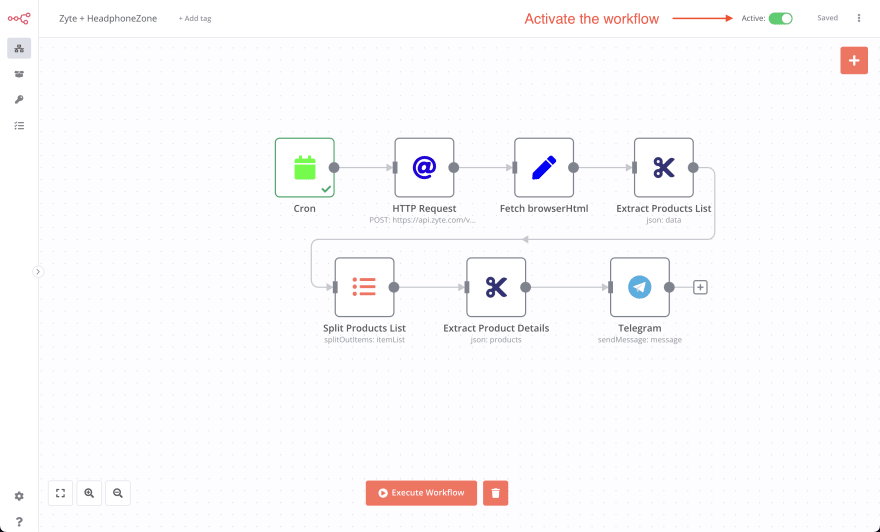
Активируйте рабочий процесс
Наконец, мы готовы развернуть наш рабочий процесс. Перед этим убедитесь, что вы выполнили все шаги учебника, ваш рабочий процесс должен выглядеть следующим образом. Вы можете активировать рабочий процесс в правом верхнем углу приложения n8n, и готово! Теперь ваш рабочий процесс активен и будет уведомлять вас, когда появится какое-либо предложение.
Что дальше?
Наш рабочий процесс по-прежнему размещен на нашем рабочем столе / локальной машине. Поэтому, если ваш компьютер выключен в течение времени срабатывания, рабочий процесс не будет работать, и вы пропустите удивительные предложения.
Вы можете использовать облако n8n, чтобы развернуть свой рабочий процесс в облаке. Вы можете развернуть n8n на своих серверах.
Кроме того, наш рабочий процесс собирает данные только с первой страницы раздела распродаж. Ему также нужна логика пагинации.
Каково же решение?
Вы можете изучить Zyte Auto Extract API, который берет на себя логику парсинга, пагинацию и все болезненные аспекты парсинга.
Счастливого вам парсинга! На этом я, Пратик Пармар, заканчиваю. До свидания!